
Als het vroeger op zondag ging over Chinezen, was de discussie wie de babi pangang met witte rijst moest ophalen voor Studio Sport begon. Tegenwoordig gaat het over DeepSeek’s CEO Liang Wenfeng, die uit het niets leek te verschijnen om iedereen, van Silicon Valley tot Washington en Wall Street, de stuipen op het lijf te jagen.
Blijkbaar heeft niet iedereen gezien dat China bezig is om in recordtijd de sprong te maken van een agrarische naar een post-industriële samenleving. Wat zal er in Beijing en Shanghai zijn gegniffeld toen er afgelopen week Chinees Nieuwjaar werd gevierd.
Vorige week schreef ik al dat Silicon Valley wakker lag van DeepSeek en dinsdag kon ik eraan toe voegen dat Wall Street zwaar overtrokken had gereageerd. Vandaag een poging om de winnaars en verliezers in kaart te brengen, op korte en lange termijn, van de opkomst van DeepSeek.
Wie is Liang Wenfeng?
Maar eerst: wie is Liang Wenfeng, de oprichter en CEO van DeepSeek? Bijzonder aan Wenfeng is zijn achtergrond als oprichter van een hedgefonds: High Flyer.
“Toen we hem voor het eerst ontmoetten, was hij een ontzettend nerdy man met een vreselijk kapsel die sprak over het bouwen van een cluster van 10.000 chips om zijn eigen modellen te trainen. We namen hem niet serieus,” aldus een van Liang’s zakenpartners tegen de Financial Times.
In zijn tijd bij High Flyer begon Liang al in 2021 met het kopen van Nvidia-apparatuur en leerde hij de verschillende mogelijkheden om algoritmes te ontwikkelen voor AI-toepassingen, die hij nu toepast bij DeepSeek. Opmerkelijker is dat het plotselinge succes van DeepSeek wordt gedreven door Gen Z nieuwkomers met een diverse achtergrond. Liang houdt van oorspronkelijkheid en creativiteit van jonge slimmerikken en hecht minder aan ervaring.
Ook sprak Liang over het aannemen van literatuurfanaten in de engineering-teams om de AI-modellen van DeepSeek te verfijnen. “Iedereen heeft zijn eigen unieke pad en brengt zijn eigen ideeën mee, dus er is geen noodzaak om hen te sturen.” Dit is vooral aardig om te lezen in de week dat Mark Zuckerberg er prat op gaat dat hij alle diversiteitsprogramma’s bij Meta afschaft, in een poging in het gevlei te komen bij de regering-Trump.
OpenAI toch $300 miljard waard?
Volgens de Wall Street Journal zou het Japanse SoftBank een investeringsronde van $40 miljard leiden in de ChatGPT-maker, waarvan een deel moet worden besteed aan het Stargate AI-infrastructuurproject. Met een waardering van $300 miljard zou OpenAI de op één na meest waardevolle startup ter wereld worden, achter SpaceX van Elon Musk, de grote rivaal van OpenAI-CEO Sam Altman.
Het zou bijzonder knap zijn als het Altman lukt om op die stratosferische waardering geld op te halen voor zijn miljarden verslindende bedrijf, in de week dat wereldwijd wordt getwijfeld aan zijn visie en zijn technologische architectuur. Maar laten we SoftBank niet te hoog inschatten: het is dezelfde club en dezelfde man, Masayoshi Son, die tientallen miljarden verbrandde in WeWork; tot het faillissement aan toe. De vraag is: waarom wil er niemand anders dan SoftBank instappen op deze waardering?
Is Stargate sciencefiction?
Zowel OpenAI als SoftBank hebben verklaard tientallen miljarden te zullen investeren in Stargate, het op $500 miljard begrote AI-infrastructuurpoject dat de Amerikaanse hegemonie op technologiegebied zou moeten bezegelen. Het gekke is dat OpenAI dat geld helemaal niet heeft en SoftBank ook niet. Dus als SoftBank investeert in OpenAI, dat daarmee investeert in Stargate, is het in feite een kwestie van vlek op vlek.
The Verge publiceerde een heldere analyse van het Stargate-project. Als Stargate faalt, zou dat niet zomaar het einde van een startup betekenen. Het zou een dure reality check zijn voor een hele industrie die beweert de wereld te transformeren door pure rekenkracht.
Altman presenteert zichzelf graag als de hoofdpersoon in een klassiek sciencefictionverhaal: de visionair die belooft de samenleving te transformeren door technologische macht. Maar zoals in veel sci-fi verhalen is de interessantste vraag niet of de technologie werkt, maar wat er gebeurt als menselijke ambitie botst met natuurkundige beperkingen.
Over pakweg een jaar zullen we weten of Stargate het begin was van Amerika’s AI-revolutie, of gewoon een techno-optimistische fantasie die niet kon overleven in de echte wereld.
DeepSeek’s werkelijke kosten
Dan naar een veelbesproken onderwerp: de kosten die DeepSeek zou hebben gemaakt om het veelgeprezen R1-model te ontwikkelen. Daarover circuleren de wildste verhalen, terwijl DeepSeek er zelf redelijk transparant over was:
“Ten slotte benadrukken we opnieuw de economische trainingskosten van DeepSeek-V3, zoals samengevat in Tabel 1, bereikt door onze geoptimaliseerde co-ontwerpen van algoritmes, frameworks en hardware.
Tijdens de pre-trainingsfase vereist het trainen van DeepSeek-V3 op elke biljoen tokens slechts 180K H800 GPU-uren, oftewel 3,7 dagen op ons cluster met 2048 H800 GPU’s. Daardoor is onze pre-trainingsfase voltooid in minder dan twee maanden en kost het in totaal 2,664M GPU-uren. Gecombineerd met 119K GPU-uren voor contextlengte-uitbreiding en 5K GPU-uren voor post-training, kost DeepSeek-V3 in totaal slechts 2,788M GPU-uren voor volledige training.
Als we aannemen dat de huurprijs van een H800 GPU $2 per GPU-uur is, bedragen onze totale trainingskosten slechts $5,576M. Let op: de bovengenoemde kosten omvatten alleen de officiële training van DeepSeek-V3 en niet de kosten die verband houden met eerdere onderzoeks- en afbraaktests van architecturen, algoritmes of data.“
Het gaat om het (door mij) vet gemaakte deel: alle eerdere kosten zijn niet opgenomen in de kostenberekening. Het is alsof je de kosten van de maaltijden van een bodybuilder berekent op de dag van de wedstrijd, zonder mee te nemen hoeveel jaar het heeft gekost om op de wedstrijddag te verschijnen. De ervaringen en de ontwikkelkosten van High Flyer heeft Liang sowieso buiten beschouwing gelaten.
Goedkopere AI: wie profiteert?
Nog veel interessanter dan het kostenaspect, is dat DeepSeek de mogelijkheid biedt om het model lokaal te installeren en erop verder te ontwikkelen. Microsoft CEO Satya Nadella wees direct op Jevons Paradox.
Kort samengevat: juist door de verlaagde kosten zal het gebruik van een innovatietoenemen. Het lijkt erop dat Nadella daarin gelijk gaat hebben. Op de lange termijn is de ‘commoditisering’ van AI-modellen en goedkopere inferentie zoals aangetoond door DeepSeek, gunstig voor Big Tech. Microsoft hoeft bijvoorbeeld minder uit te geven aan datacenters en GPU’s, terwijl het profiteert van een verhoogd AI-gebruik door lagere inferentiekosten.
Amazon is ook een grote winnaar: AWS is er grotendeels niet in geslaagd een eigen kwalitatief hoogstaand AI-model te ontwikkelen, maar dat maakt niet uit als er hoogwaardige open-source modellen beschikbaar zijn die het tegen veel lagere kosten kan aanbieden.
Apple profiteert ook
Drastisch verlaagde geheugeneisen voor inferentie maken AI op iPhones veel haalbaarder. Apple Silicon maakt gebruik van een uniforme geheugenarchitectuur, waarbij de CPU, GPU en NPU (neural processing unit) toegang hebben tot een gedeelde geheugenpool, betoogt Stratechery in een uitstekend stuk. Hierdoor heeft Apple’s hardware feitelijk de beste consumentenchip voor inferentie. Nvidia’s gaming GPU’s bereiken bijvoorbeeld een maximum van 32GB VRAM, terwijl Apple’s chips tot 192GB RAM ondersteunen.
Meta de grootste winnaar
AI staat centraal in Meta’s langetermijn-strategie en een van de grootste obstakels tot nu toe was de hoge kostprijs van inferentie. Als inferentie en training veel goedkoper worden, kan Meta zijn AI-gedreven bedrijfsmodel versnellen en efficiënter uitbreiden.
Het is verstandig dat Zuckerberg naar verluidt diverse war rooms heeft opgezet om te bepalen hoe Meta zal reageren op de introductie van DeepSeek. Waar op korte termijn wordt gedacht dat DeepSeek een bedreiging vormt voor de AI-strategie van Meta, zal een structurele verlaging van de ontwikkelkosten van AI juist leiden tot een enorm voordeel voor Meta, dat op weg is om alleen dit jaar al $65 miljard in AI-ontwikkeling te investeren.
Het grootste deel daarvan wordt besteed aan hardware en datacenters. Als dat soort investeringen kunnen worden geminimaliseerd door de aanpak van DeepSeek te imiteren, zal Meta zijn netto winst fors zien oplopen zonder de concurrentiepositie te verzwakken.
Google de verliezer?
Hoewel Google ook profiteert van lagere kosten, is elke verandering ten opzichte van de huidige status quo voor Google waarschijnlijk een netto nadeel. Elke zoekopdracht in OpenAI, DeepSeek of een Meta-agent, gaat ten koste van een zoekopdracht op de zoekmachine van Google.
Ondanks alle pogingen en honderden acquisities van de laatste decennia, is Google voor de omzet en winst nog steeds grotendeels afhankelijk van de zoekmachine. Het is nog maar de vraag of Google erin slaagt dat verkeer ’terug te leiden’ van de AI-agenten en chatbots waar de wereld zo gretig gebruik van maakt, naar de AI-tools van Google.
Nvidia niet verslagen door DeepSeek
Ondanks DeepSeek’s doorbraak heeft Nvidia volgens Stratechery twee grote verdedigingslinies:
- CUDA is de voorkeursprogrammeertaal voor iedereen die deze modellen ontwikkelt, en CUDA werkt alleen op Nvidia-chips.
- Nvidia heeft een enorme voorsprong als het gaat om de mogelijkheid om meerdere chips te combineren tot één grote virtuele GPU.
Deze twee verdedigingslinies versterken elkaar. Zoals eerder vermeld, als DeepSeek toegang had gehad tot H100’s, zouden ze waarschijnlijk een grotere cluster hebben gebruikt om hun model te trainen, simpelweg omdat dat de makkelijkste optie was. Het feit dat ze dat niet deden en beperkt waren door bandbreedte, bepaalde veel van hun beslissingen op het gebied van modelarchitectuur en trainingsinfrastructuur.
DeepSeek heeft laten zien dat er een alternatief bestaat: met zware optimalisatie kunnen indrukwekkende resultaten worden behaald op zwakkere hardware en met lagere geheugenbandbreedte. Meer betalen aan Nvidia is dus niet de enige manier om betere modellen te ontwikkelen.
Toch zijn er drie factoren die nog steeds in het voordeel van Nvidia werken.
- Ten eerste, hoe krachtig zou de aanpak van DeepSeek zijn als deze werd toegepast op H100’s of de aankomende GB100’s? Het feit dat ze een efficiëntere manier hebben gevonden om rekenkracht te gebruiken, betekent niet dat meer rekenkracht niet nuttig zou zijn.
- Ten tweede, lagere inferentiekosten zullen op de lange termijn waarschijnlijk leiden tot een breder gebruik van AI. Microsoft-CEO Satya Nadella bevestigde dit onlangs in zijn late-night tweet over Jevons paradox.
- Ten derde, redeneermodellen zoals R1 en o1 halen hun superieure prestaties uit het gebruik van meer rekenkracht. Zolang de kracht en capaciteiten van AI afhangen van meer computing power, blijft Nvidia hiervan profiteren.
Ook zal Nvidia bij een grotere markt profiteren van omzetstijging bij de goedkopere chips, al zal het in die markt wel hinder ondervinden van concurrenten zoals AMD.
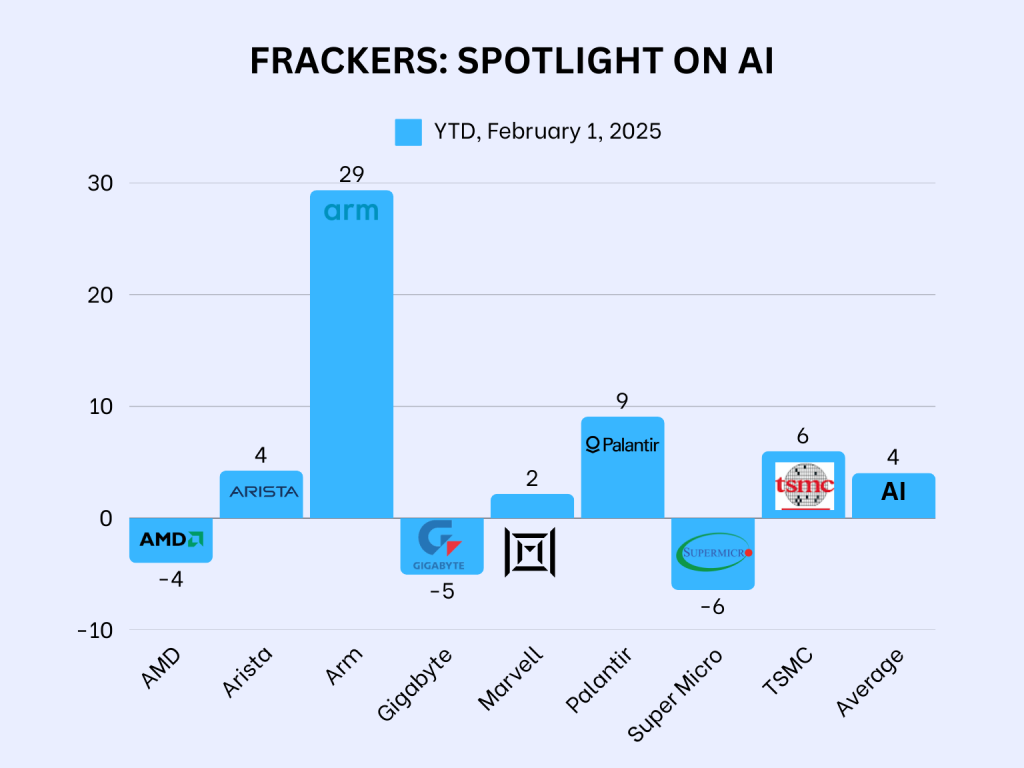
DeepSeek dacht 28 seconden over een hotdog
Joanna Stern van de Wall Street Journal deed een grappige test met DeepSeek en ontdekte hoe het verschilt van OpenAI’s ChatGPT en Anthropic’s Claude. In tegenstelling tot OpenAI’s redeneermodellen toont DeepSeek zijn volledige denkproces. Toen werd gevraagd of een hotdog een sandwich is, dacht DeepSeek er 28 seconden over na en antwoordde met: “Eerst moet ik begrijpen wat de definitie is van een sandwich.” Het illustreert dat er geen specifieke vorm van AI bestaat, die het best werkt voor alle vraagstukken.
De opmars van AI in de gehele samenleving is onomkeerbaar en door de aanpak van DeepSeek, die veelvuldig zal worden gekopieerd, zal de markt alleen groter worden. Ondanks alle onheilstijdingen van afgelopen week op Wall Street is het daarom boeiend dat over de gehele maand januari gezien, de terugval van wat ik beschouw als AI-aandelen, enorm meevalt.
De 29% stijging van ARM is opmerkelijk en is grotendeels gebaseerd op de deelname van ARM in Stargate. Het bijzondere is dat SoftBank eigenaar is van ARM en de kans daarom groot is dat Masayoshi Son de aandelen in ARM als onderpand zal gebruiken bij het aantrekken van leningen, waarmee SoftBank vervolgens de investeringen in OpenAI en in Stargate kan betalen. De tijd zal leren of deze aanpak leidt tot een wolkenkrabber, of een kaartenhuis.
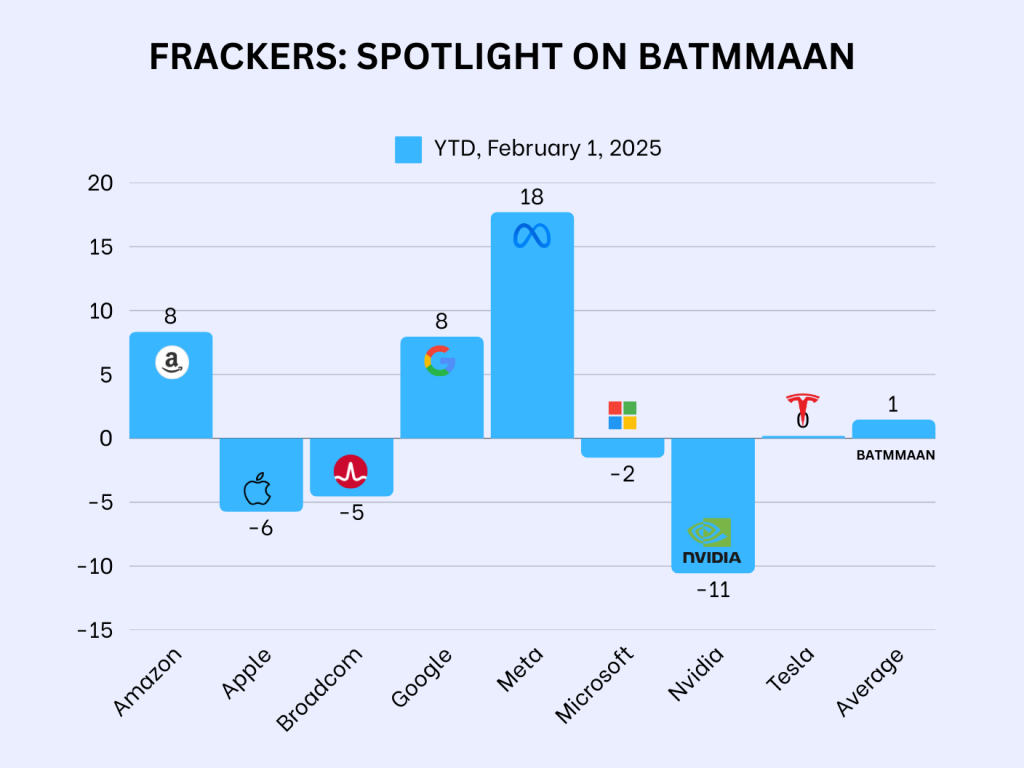
Wat kochten Amerika’s tech-miljardairs van Trump?
President Trump heeft zich vaak vijandig uitgelaten over grote technologiebedrijven en hun leiders, waarbij hij Facebook bijvoorbeeld een “vijand van het volk” noemde en Jeff Bezos bestempelde als “Jeff Bozo.” Toch stonden deze heren op de voorste rij bij de inauguratie, nadat ze aanzienlijke bedragen hadden gelapt. Dit was uiteraard geen toeval en de technologiesector wil snel iets terug van Trump. Bloomberg ging ze stuk voor stuk af en bracht in kaart wat ze elk willen bereiken.
Als we aan het eind van de tweede week in Trump’s tweede regeerperiode de balans opmaken over de prestaties van de Big Tech-aandelen in de maand januari, blijkt dat de resultaten op korte termijn nog niet zijn waarop Trumps nieuwe tech-vrindjes hadden gehoopt. Ondanks alle presidentiële decreten en benoemingen van Trump zijn de beursresultaten, op zijn zachtst gezegd, nogal gemengd.
Wat vooral opvalt, is dat de de beleggers over de tech-sector als geheel sterk verdeeld zijn. Meta steeg vooral door goede kwartaalcijfers, maar hoe kon Microsoft dalen terwijl Google juist steeg? Daalde Apple in januari door de kans op een handelsoorlog met China? Het is vreemd dat de financiële media vooral oog hadden voor de resultaten van afgelopen week en eraan voorbij gingen wat er eerder in de maand aan koerszwenkingen plaatsvonden. Denk bijvoorbeeld aan Palantir, dat bijna 10% steeg in januari en al 385% in het laatste jaar.
Huang bij Trump, Liang bij Li Qiang
Trump en Nvidia’s CEO Jensen Huang bespraken vrijdag tijdens een ontmoeting in het Witte Huis de impact van DeepSeek en mogelijke beperkingen op de export van AI-chips naar China. Huang zal zeker aan de eventuele gevolgen voor de koers van Nvidia hebben gedacht.
Ook DeepSeek’s Liang Wenfeng had deze week een ontmoeting met een belangrijke politicus: als enige vertegenwoordiger van de AI-sector had hij een ontmoeting met premier Li Qiang, de op één na machtigste man van China. Beide ontmoetingen onderstrepen het belang van technologie voor de economische macht in de nieuwe, deels door AI bepaalde wereldorde.
Palantir-CEO Alex Karp zei tegen CNBC dat de opkomst van DeepSeek een teken is dat de VS sneller moet werken aan de ontwikkeling van geavanceerde AI. “Technologie is niet per definitie goed en kan bedreigingen vormen in de handen van tegenstanders. We moeten dat erkennen, maar dat betekent ook dat we harder moeten rennen, sneller moeten gaan en een nationale inspanning moeten leveren.”
Saai: succes begint met huiswerk
De technologiesector op de koffie bij de macht; het doet weemoedig terugdenken aan het moment, nog geen dertig jaar geleden, dat premier Kok van een kind leerdehij een muis moest vasthouden. Europa is geen overweging meer in het geopolitieke geschuif tussen continenten; hoe kan het, met zoveel talent onder een half miljard mensen?
De Maleisische komiek Ronny Chieng vatte het probleem van het westen perfect samen: mensen zijn bereid om te sterven voor hun land, maar ze willen er geen huiswerk voor maken. Chieng heeft het over Amerika, maar het gaat net zo goed op voor Europa.